
众调网联合“中关村大数据产业联盟汽车大数据专委会”推出“大数据100分”论坛,每晚9点开始,于“中关村大数据产业联盟”微信群进行时长100分钟的交流、探讨。
【大数据100分】互联网公开大数据的应用探索
主讲嘉宾:顾程 上海微趣网络科技有限公司 联合创始人兼CEO
主持人:海略咨询总经理 汽车大数据专委会主任 郑鑫
承办方:中关村大数据产业联盟
嘉宾介绍:
顾程:2005年毕业于上海交通大学,2011年联合创办微趣,之前先后任职于微软全球技术支持中心 、上海市政府软件服务中心。2013年作为项目带头人微趣公司的微博舆情系统项目获得第六届国家王选新闻科学技术奖二等奖。
以下为分享实景全文:
顾程:大家好!我是上海微趣网络科技有限公司(http://abit.io)的顾程。我们公司自2009年起就专注于互联网公开大数据的采集与分析处理技术。过去几年我们发现社交网络的出现与移动互联网的普及,使用户更愿意在互联网中发布内容,从而使互联网公开数据发生了大爆炸。但是社交网络作为大数据的源头都开始做垂直搜索,并且将社区封闭起来(需要注册才能进入查看内容)因此公开数据就被分割成了网站内容,社交网络内容多个源,例如大家现在搜索一个关键词,可能需要新浪微博,腾讯微博,百度,微信公众号这么来用。我们公司这些年做的一些比较有意思的事情,就是将这些源的数据再次整合在了一起,并提供了一些商用的数据检索服务。
目前日常采集包括境内外的微博(新浪,腾讯,Twitter),数百万微信公众号和热门网页内容。数据库中积累的数据包括超过300亿条微博内容,超过6亿真实用户的公开社交资料和记录这些用户之间关注关系的超过100亿条关系链数据以及近3年的主要热门网页媒体报道和微信公众号文章。基于这些数据,我们做了很多方面的应用探索,今天会拿出一些例子与大家进行分析。
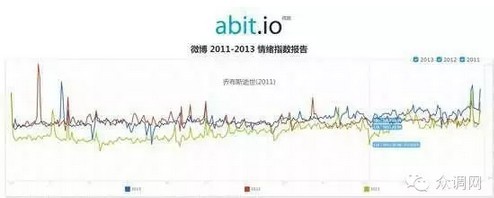
这是我们在去年发布的基于上百亿条中文微博数据分析获得的中国情绪指数报告,报告采用2011年到2013年的所有中文微博数据(正是微博最活跃的3年)。基于文本判断情绪正负面一直都是语言分析领域的一个难点,我们并未纠缠在中文语意之上。由于社交网络更丰富自由的表现形式,大部分用户都非常习惯于使用表情符号,我们将新浪和腾讯提供的数百个常用表情进行了分类,分成正面,负面及中性,然后统计得出了这样一个情绪指数的曲线。最后发现在掌握数亿用户全面海量数据之后,社会总体情绪会非常稳定,任意波峰和波谷基本都是对应了具体的重大事件的,例如上图中2011年10月6日,乔布斯逝世就造成了一个较大的情绪低谷。基于这样的统计我们基本可以得出每年中国民众情绪最好及最坏的10个节点与事件。具体指数发布在http://abit.io/emotion/,大家可以随时查看。
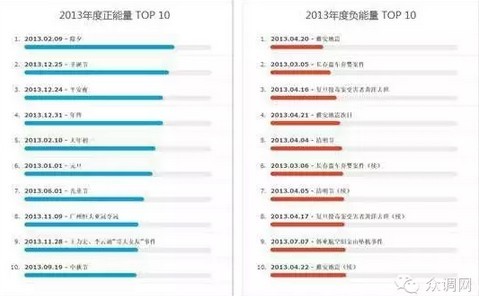
例如2013年,我们可以发现中国民众在重要节假日的时候情绪都会非常好,当然也包括了广州恒大亚冠夺冠及王力宏李云迪的“哥大女友”事件都使大家的情绪不错,相对应的情绪最差的节点基本全部与一些具有全国影响力的负面事件有关,比如复旦投毒,雅安地震,长城盗车弃婴案等等。
其实基于这些数据和表情符号的利用,我们完全可以做出更多细化的情绪指数。例如某一段时间内上海与北京的情绪对比,甚至上海和北京地区民众在提及房价或空气质量的时候的情绪波动对比等。当然也可以引入例如提及车型,车生活等关键词时候的情绪波动。目前在这点上我们并未深入,但国外有相关研究表明利用Twitter的情绪指数可以准确预测未来股市的走向,且成功率接近90%,因此群体情绪的利用还有待后续深入的业务融合。
我们在最早获取并研究互联网公开数据之初就选择了社交网络的数据,因为我们认为数据利用最终会落实到一个个体上,即对于个体用户的相关数据分析,以了解这个用户的特征,这也是常见的大家热门讨论的话题,系统利用大数据会比你自己更了解自己。社交网络数据除了用户本身所产生的大量数据之外,其社交关系网也可以提供大量的相关数据。在我们搞清楚每个用户的强关系网络之后,就可以让个体相关数据进行二次爆炸,即使对于一些只看不发的深度读者社交用户,只要他是实名用户,就必定会有其亲属,同事,同学,朋友等强关系网存在,他们所发布的信息都可以用来分析一个用户的特征,物以类聚的概念在这里非常适用。下面我来举一些我们分析个体用户的例子。
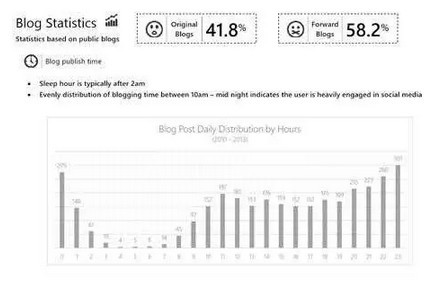
我们在社交网络中选取了一个随机用户,其3年的发布内容总数也就在1000左右,不算深度社交用户。我们统计了其所有的发布时间,得出了上面这张分布图以了解这个用户的作息习惯。从这个图表中,我们可以了解到该用户基本在半夜2点以后入睡,并且会在办公时间活跃在网络上。该分析我们是与51job合作进行研究利用社交网络数据使招聘更精准而做的。这个案例中如果招聘企业不希望员工在上班时间使用社交网络,那这个用户就是不合适的。
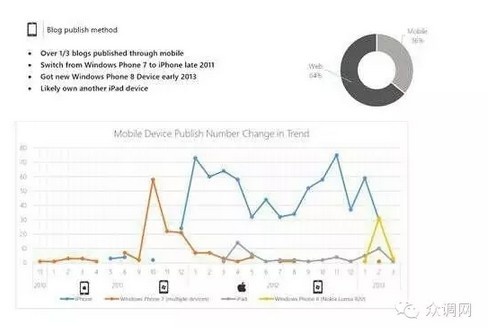
这是该用户在过去3年中的手持设备的变化情况。从中我们可以了解到该用户在2011年底将winphone7的手机换成了iphone4s,在2013年2月份,将iphone换成了winphone8的手机,并且可能拥有一台iPad的设备,因为代表Ipad的那根线使用频率很低,很有可能是借用了家人的设备,而非常用设备。这些信息可以告诉我们用户消费手机的习惯,包括更换频率,习惯的手机平台和手机价格等。由此可以推断该用户的消费能力和习惯。这里就是一个很好的数据比用户本身更懂用户的案例,如果要群里各位描述下各自在过去三年使用过哪些手机我想大家应该大多数还是能够回答的,但是具体几月几号换的,恐怕知道的就基本没有了。

接下来继续和大家分享一些我们在汽车领域的实践,这是我们给Jeep大切诺基做的一些数据分析,该分析是为了找出大切诺基车主的特征。我们在数亿用户中挑出了数百个明确拥有大切诺基的用户,使用方法例如曾经提及过自己拥有一辆大切诺基并且有提车或者保养的相关内容发布。找出用户之后,我们将这些用户历史上发过的所有内容进行分词,处理成词云之后就如上图所示。左边是我们随机了220万的随机用户,右边是大切的车主,可以发现明细的不同之处,大切的车主更多讨论例如企业,投资,政府,汽车等更严肃的话题,而普通用户则更专注于一些生活类的关键词。
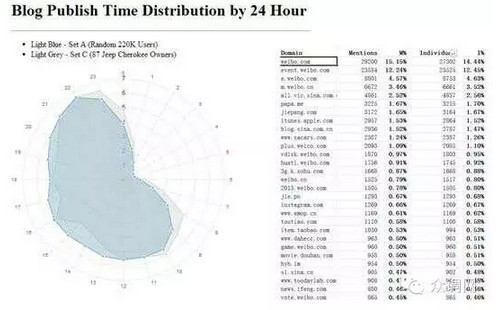
这是我们从2组用户群体的作息与网络访问偏好得出的结果。大切车主在作息习惯上会比普通用户睡得更晚,起得更早,但在下午13:00到晚上21:00这个时间段相比普通用户更多的离开互联网。 除此之外我还发现拥有这辆越野车的男性用户是女性用户的3倍左右,这些数据可以帮助这款车确定品牌形象,确定消息发布时间,发布渠道等给出一定的指向性。
目前我们公司的主营业务主要是向政府和企业提供实时情报服务,其中上汽集团就是我们的服务使用企业之一。这类需求是我们探索下来能体现大数据技术核心价值的一个领域。由于互联网进入了大数据时代,社交网络鼓励用户创造实时内容的模式,以及移动互联网的普及,现在随时都有大量的信息产生,我们在这个领域的真实应用就是实时将采集到的大量数据纳入现有海量数据进行实时计算,从中获得有价值的数据(也就是情报)。由于没有人能够预测下一秒的信息变化,实时掌握整个互联网的动态就变得很迫切,数据处理和获取难度会变得非常高,这时候大数据的硬技术就派上了用场。后面会讲到关于大数据的核心利用价值与硬技术。
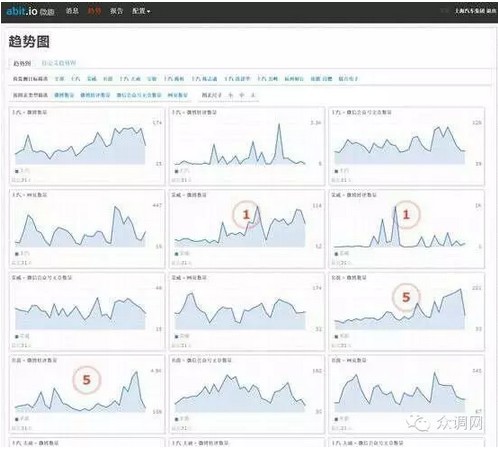
以上汽为例,上汽利用我们的实时系统监测整个互联网上的相关消息,除了监测本身的高管与产品之外,还监测了部分竞争对手的产品,可以了解到包括一些4s店在内,实时在微博,微信,网页上发布的各类消息,由此快速应对。上面这个图标是提及上汽关注的一些关键词的全网走势,红色数字是一些重要消息的提醒,我们后台有机器学习的程序来自动判别重要及负面消息。这些图表都可以进行点击来找到具体对应数据。

这些消息随时都会更新,并且我们会实时计算一个热度的数值进行排序,由于大数据产生的一些负面效果包括数据量大量增大,包括数据可信度大幅下降,提供热度排序和真假识别的实时计算技术可以提供更全面有效的数据内容。热度一方面会随着时间衰减,一方面会随着传播放大,实现实时排序。
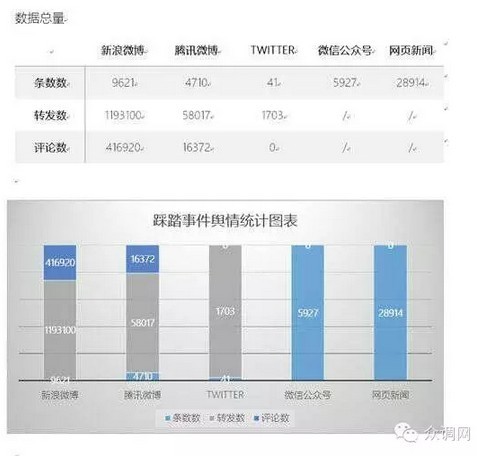
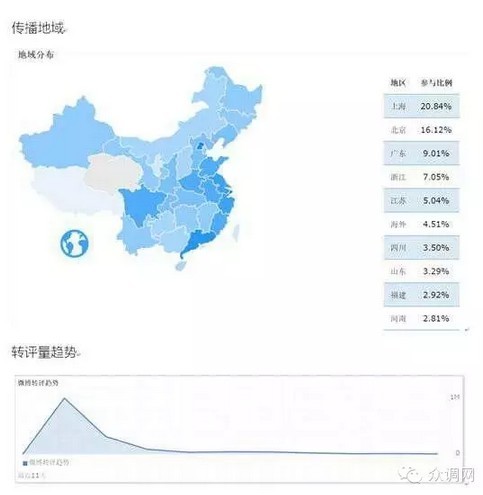
在这次外滩踩踏事件发生之后,由于上海市黄浦区和上海市委宣传部都使用了我们提供的舆情系统,我们也特别参与了事件后续舆情工作的技术支持;导致在一个全国关注,产生上百万转评的重大事件发生后,快速发现了所有的谣言,质疑,线索并在之后的官方发布会中有侧重的先后对社会关注进行了回应;事后包括公安,国安在内所有专业部门都对我们的系统在本次事件中起到的作用给予高度认可。试想一下面对数百万相关的言论,无时无刻不在新增,发酵,如果没有大数据的实时计算技术支持,如何能够随时找到最重要的舆论点进行回应,将永远有限的人力和时间用在最重要的环节内。
以上这些都是我们在这些年的过程中摸索的我们掌握的数百亿条数据可能和现实商业领域结合的应用探索。但是从我们的角度出发,我们认为大数据的核心价值目前在咨询,预测领域还无法得到体现。最简单的例子就是央视发布了一个全国姓名统计,告诉大家全国姓氏和名字的排名,然后说这是大数据。其实我们认为不是,只是你得出结论的使用的数据量很大而已。这个排名有很多抽样的方法可以得到差不多的排名顺序,并且没有任何业务会敏感排名的细微差异,那么这个利用大数据的结果就是无效的,或者说不特别适用,特别对于企业而言,没有任何人愿意为此买单,特别是调用和运算全国人口姓名全部数据的成本与这个排名产生的价值是不匹配的,这是最典型的大量数据的数据分析,而非大数据。
我们认为大数据4个V中的Velocity(快速)才是大数据应用的核心。大数据并非是一个概念,而是有硬技术的。我觉得有一个讲法说的不错,大数据技术就是解决传统技术处理不了的数据需求。以我们公司的核心技术为例,我们使用了分布式文件系统的架构来并行加速磁盘读写,使用了自主研发的非关系型数据库来大幅增强数据库吞吐能力,就是为了在相同硬件基础下,获得10-100倍的计算性能的提升。由此我们节约了大量的成本提供了更好的数据服务,这也就成为了核心的竞争力。
综上所述,大数据在2014年成为了一个大热点,但是在具体使用的业务切入点选择上还有很长的路要走,而且大数据技术作为所有真实业务中的一环,只是提供了在业务遇到数据处理瓶颈时候的解决方法,并非一定会成为颠覆所有行业的杠杆。这是我们在这一领域这些年的体会,希望得到各位的指正,今天的分享完了。谢谢!




